



全部
大模型加速器
通用识别
图像智能处理
票据识别
文档格式转换
AI篡改检测
卡证识别

通用文字识别
通过前沿的深度学习技术,对各种表格,图片,文档、证件、面单等多种通用场景进行快速、精准的文字检测和识别,支持多页PDF输入。支持简体中文/繁体中文/英文/数字/西欧主流语言/东欧主流语言等共52种语言,同时支持印刷体、手写体、倾斜、折叠、旋转等。
类型: 通用识别
¥0.025/页 起

通用表格识别
支持识别图片/PDF格式文档中的表格内容,包括有线表格、无线表格、合并单元格表格,同时支持单张图片内的多个表格内容识别,返回各表格的表头表尾内容、单元格文字内容及其行列位置信息。
类型: 通用识别
¥0.025/页 起

通用文档解析
识别文档或图片中的文字信息,并按常见的阅读顺序进行还原,赋能大语言模型的数据清洗和文档问答任务。支持标准的金融报告、国家标准、论文、企业招投标文件、合同、文书、工程图纸等文档内容。支持 PDF、Word(doc/docx)、常见图片(jpg/png/webp/tiff)、HTML 等文件格式。
类型: 大模型加速器
¥0.042/页 起
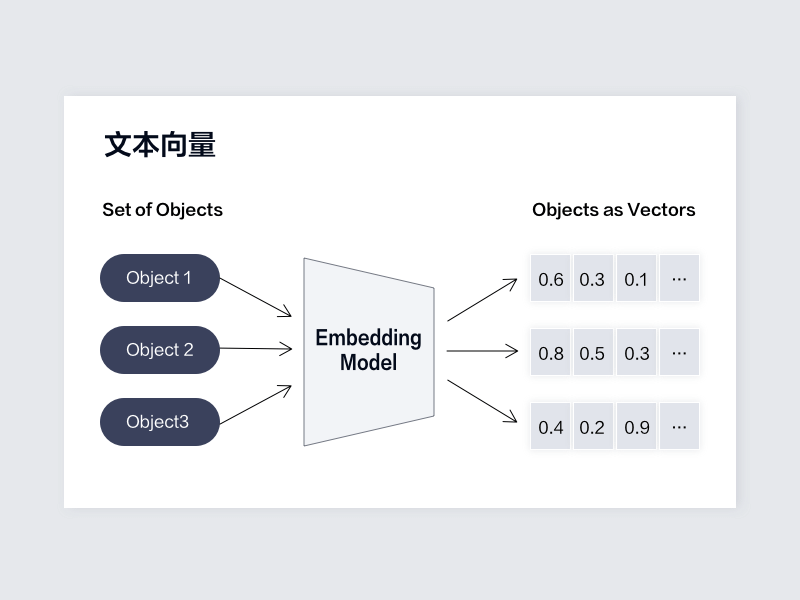
通用文本向量
Textin文本向量模型(acge_text_embedding)是合合信息自主研发中文文本向量化模型,为知识问答、信息检索、长文本信息抽取等场景提供支持;acge模型较小,输入文本长度为1024,支持可变输出维度,满足绝大部分场景的需求。
类型: 大模型加速器
¥0.012/次 起

智能文档抽取
TextIn智能文档抽取平台为您提供在线文档智能信息提取服务。该平台基于合合信息强大的文字识别能力,结合了文档解析、文档检索和文本生成三项核心技术。文档解析采用版面分析技术,文档检索使用混合多路检索,而文本生成依托于垂直领域的语义模型。您可以在线体验多种场景下的智能文档抽取效果。
类型: 大模型加速器
¥0.108/页 起

国内通用票据识别
利用合合信息多年积累的票据文字OCR识别能力,识别包含纸质医疗发票、电子医疗发票、全电票、航空运输电子客票行程单、铁路电子客票在内的23大类、30小类国内通用票据,提取其中的信息,并以整理成标准结构化的Key/Value形式返回或导出。支持单页面多票的切分识别,支持输入多种通用图片格式、多页PDF、多页OFD格式。
类型: 票据识别
¥0.025/张 起

图像水印去除
支持对图片中日期、logo、文字等形式的水印进行自动擦除,确保高保真处理,无痕还原图片素材。
类型: 图像智能处理
¥0.025/次 起

文档图像切边增强矫正
智能判断照片中主体文档的边缘,并进行背景切除 (文档提取),既能对形变文档进行矫正,又能同时增强图像突出文字(矫正+增强),支持识别背景复杂的文字内容,返回切边后的图像。
类型: 图像智能处理
¥0.03/次 起

PDF转Word
提供高并发高可靠的API,将PDF文档转换为Word。转换出的文件尽可能保持PDF原有格式,强化易读性。
类型: 文档格式转换
¥0.03/次 起

图片转word
图片版面还原,把图片还原为doc文件,保留照片中文档的版面格式的同时,提取图片中的文字,包含表格图片、手写文字,并支持印章单独提取,实现印章的提取,分离和还原等功能。
类型: 文档格式转换
¥0.03/次 起
微信扫一扫
体验手机端识别效果


企业智能应用


合同机器人
合同文本精准比对和智能纠错

文字识别训练云平台
无需OCR开发基础的全流程一站式开发平台









